Reinforcement learning (RL) can be used to train a policy to perform a task via trial and error, but a major challenge in RL is learning policies from scratch in environments with hard exploration challenges. For example, consider the setting depicted in the door-binary-v0 environment from the adroit manipulation suite, where an RL agent must control a hand in 3D space to open a door placed in front of it.
An RL agent must control a hand in 3D space to open a door placed in front of it. The agent receives a reward signal only when the door is completely open.
{kind=link}
Since the agent receives no intermediary rewards, it cannot measure how close it is to completing the task, and so must explore the space randomly until it eventually opens the door. Given how long the task takes and the precise control required, this is extremely unlikely.
For tasks like this, we can avoid exploring the state space randomly by using prior information. This prior information helps the agent understand which states of the environment are good, and should be further explored. We could use offline data (i.e., data collected by human demonstrators, scripted policies, or other RL agents) to train a policy, then use it to initialize a new RL policy. In the case where we use neural networks to represent the policies, this would involve copying the pre-trained policy’s neural network over to the new RL policy. This procedure makes the new RL policy behave like the pre-trained policy. However, naïvely initializing a new RL policy like this often works poorly, especially for value-based RL methods, as shown below.
A policy is pre-trained on the antmaze-large-diverse-v0 D4RL environment with offline data (negative steps correspond to pre-training). We then use the policy to initialize actor-critic fine-tuning (positive steps starting from step 0) with this pre-trained policy as the initial actor. The critic is initialized randomly. The actor’s performance immediately drops and does not recover, as the untrained critic provides a poor learning signal and causes the good initial policy to be forgotten.
{kind=link}
With the above in mind, in “Jump-Start Reinforcement Learning” (JSRL), we introduce a meta-algorithm that can use a pre-existing policy of any form to initialize any type of RL algorithm. JSRL uses two policies to learn tasks: a guide-policy, and an exploration-policy. The exploration-policy is an RL policy that is trained online with new experience that the agent collects from the environment, and the guide-policy is a pre-existing policy of any form that is not updated during online training. In this work, we focus on scenarios where the guide-policy is learned from demonstrations, but many other kinds of guide-policies can be used. JSRL creates a learning curriculum by rolling in the guide-policy, which is then followed by the self-improving exploration-policy, resulting in performance that compares to or improves on competitive IL+RL methods.
The JSRL Approach
The guide-policy can take any form: it could be a scripted policy, a policy trained with RL, or even a live human demonstrator. The only requirements are that the guide-policy is reasonable (i.e., better than random exploration), and it can select actions based on observations of the environment. Ideally, the guide-policy can reach poor or medium performance in the environment, but cannot further improve itself with additional fine-tuning. JSRL then allows us to leverage the progress of this guide-policy to take the performance even higher.
At the beginning of training, we roll out the guide-policy for a fixed number of steps so that the agent is closer to goal states. The exploration-policy then takes over and continues acting in the environment to reach these goals. As the performance of the exploration-policy improves, we gradually reduce the number of steps that the guide-policy takes, until the exploration-policy takes over completely. This process creates a curriculum of starting states for the exploration-policy such that in each curriculum stage, it only needs to learn to reach the initial states of prior curriculum stages.
Here, the task is for the robot arm to pick up the blue block. The guide-policy can move the arm to the block, but it cannot pick it up. It controls the agent until it grips the block, then the exploration-policy takes over, eventually learning to pick up the block. As the exploration-policy improves, the guide-policy controls the agent less and less.
{kind=link}
Comparison to IL+RL Baselines
Since JSRL can use a prior policy to initialize RL, a natural comparison would be to imitation and reinforcement learning (IL+RL) methods that train on offline datasets, then fine-tune the pre-trained policies with new online experience. We show how JSRL compares to competitive IL+RL methods on the D4RL benchmark tasks. These tasks include simulated robotic control environments, along with datasets of offline data from human demonstrators, planners, and other learned policies. Out of the D4RL tasks, we focus on the difficult ant maze and adroit dexterous manipulation environments.
Example ant maze (left) and adroit dexterous manipulation (right) environments.
{kind=link}
For each experiment, we train on an offline dataset and then run online fine-tuning. We compare against algorithms designed specifically for each setting, which include AWAC, IQL, CQL, and behavioral cloning. While JSRL can be used in combination with any initial guide-policy or fine-tuning algorithm, we use our strongest baseline, IQL, as a pre-trained guide and for fine-tuning. The full D4RL dataset includes one million offline transitions for each ant maze task. Each transition is a sequence of format (S, A, R, S’) which specifies what state the agent started in (S), the action the agent took (A), the reward the agent received (R), and the state the agent ended up in (S’) after taking action A. We find that JSRL performs well with as few as ten thousand offline transitions.
Average score (max=100) on the antmaze-medium-diverse-v0 environment from the D4RL benchmark suite. JSRL can improve even with limited access to offline transitions.
{kind=link}
{kind=link}
Vision-Based Robotic Tasks
Utilizing offline data is especially challenging in complex tasks such as vision-based robotic manipulation due to the curse of dimensionality. The high dimensionality of both the continuous-control action space and the pixel-based state space present scaling challenges for IL+RL methods in terms of the amount of data required to learn good policies. To study how JSRL scales to such settings, we focus on two difficult simulated robotic manipulation tasks: indiscriminate grasping (i.e., lifting any object) and instance grasping (i.e., lifting a specific target object).
A simulated robot arm is placed in front of a table with various categories of objects. When the robot lifts any object, a sparse reward is given for the indiscriminate grasping task. For the instance grasping task, a sparse reward is only given when a specific target object is grasped.
{kind=link}
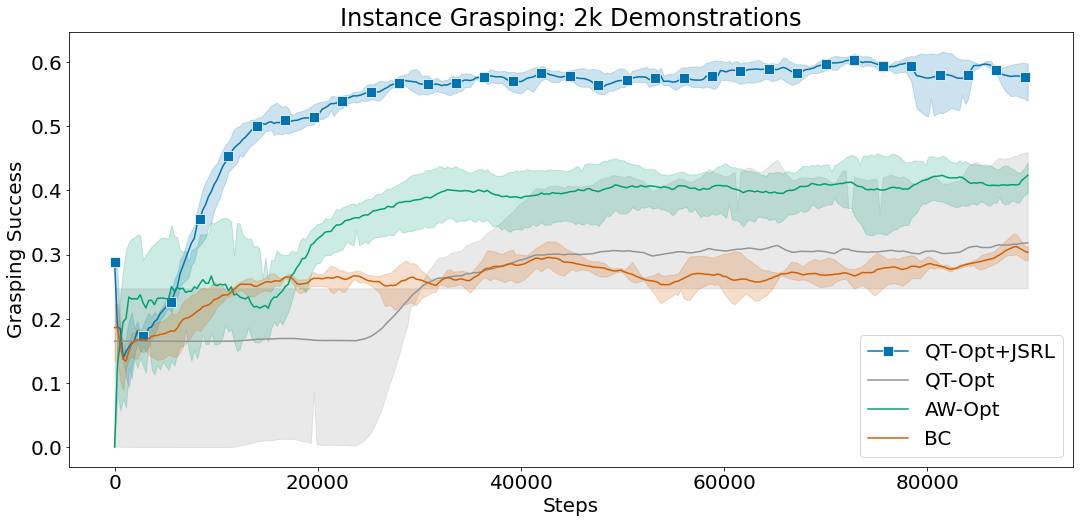
We compare JSRL against methods that are able to scale to complex vision-based robotics settings, such as QT-Opt and AW-Opt. Each method has access to the same offline dataset of successful demonstrations and is allowed to run online fine-tuning for up to 100,000 steps.
In these experiments, we use behavioral cloning as a guide-policy and combine JSRL with QT-Opt for fine-tuning. The combination of QT-Opt+JSRL improves faster than all other methods while achieving the highest success rate.
Mean grasping success for indiscriminate and instance grasping environments using 2k successful demonstrations.
{kind=link}
{kind=link}
Conclusion
We proposed JSRL, a method for leveraging a prior policy of any form to improve exploration for initializing RL tasks. Our algorithm creates a learning curriculum by rolling in a pre-existing guide-policy, which is then followed by the self-improving exploration-policy. The job of the exploration-policy is greatly simplified since it starts exploring from states closer to the goal. As the exploration-policy improves, the effect of the guide-policy diminishes, leading to a fully capable RL policy. In the future, we plan to apply JSRL to problems such as Sim2Real, and explore how we can leverage multiple guide-policies to train RL agents.
Acknowledgements
This work would not have been possible without Ikechukwu Uchendu, Ted Xiao, Yao Lu, Banghua Zhu, Mengyuan Yan, Joséphine Simon, Matthew Bennice, Chuyuan Fu, Cong Ma, Jiantao Jiao, Sergey Levine, and Karol Hausman. Special thanks to Tom Small for creating the animations for this post.
Posted by Ikechukwu Uchendu, AI Resident and Ted Xiao, Software Engineer, Robotics at Google Reinforcement learning (RL) can be used to train a policy to perform a task via trial and error, but a major challenge in RL is learning policies from scratch in environments with hard exploration challenges. For example, consider the setting depicted in the door-binary-v0 environment from the adroit manipulation suite, where an RL agent must control a hand in 3D space to open a door placed in front of it. An RL agent must control a hand in 3D space to open a door placed in front of it. The agent receives a reward signal only when the door is completely open. Since the agent receives no intermediary rewards, it cannot measure how close it is to completing the task, and so must explore the space randomly until it eventually opens the door. Given how long the task takes and the precise control required, this is extremely unlikely. For tasks like this, we can avoid exploring the state space randomly by using prior information. This prior information helps the agent understand which states of the environment are good, and should be further explored. We could use offline data (i.e., data collected by human demonstrators, scripted policies, or other RL agents) to train a policy, then use it to initialize a new RL policy. In the case where we use neural networks to represent the policies, this would involve copying the pre-trained policy’s neural network over to the new RL policy. This procedure makes the new RL policy behave like the pre-trained policy. However, naïvely initializing a new RL policy like this often works poorly, especially for value-based RL methods, as shown below. A policy is pre-trained on the antmaze-large-diverse-v0 D4RL environment with offline data (negative steps correspond to pre-training). We then use the policy to initialize actor-critic fine-tuning (positive steps starting from step 0) with this pre-trained policy as the initial actor. The critic is initialized randomly. The actor’s performance immediately drops and does not recover, as the untrained critic provides a poor learning signal and causes the good initial policy to be forgotten. With the above in mind, in “Jump-Start Reinforcement Learning” (JSRL), we introduce a meta-algorithm that can use a pre-existing policy of any form to initialize any type of RL algorithm. JSRL uses two policies to learn tasks: a guide-policy, and an exploration-policy. The exploration-policy is an RL policy that is trained online with new experience that the agent collects from the environment, and the guide-policy is a pre-existing policy of any form that is not updated during online training. In this work, we focus on scenarios where the guide-policy is learned from demonstrations, but many other kinds of guide-policies can be used. JSRL creates a learning curriculum by rolling in the guide-policy, which is then followed by the self-improving exploration-policy, resulting in performance that compares to or improves on competitive IL+RL methods. The JSRL ApproachThe guide-policy can take any form: it could be a scripted policy, a policy trained with RL, or even a live human demonstrator. The only requirements are that the guide-policy is reasonable (i.e., better than random exploration), and it can select actions based on observations of the environment. Ideally, the guide-policy can reach poor or medium performance in the environment, but cannot further improve itself with additional fine-tuning. JSRL then allows us to leverage the progress of this guide-policy to take the performance even higher. At the beginning of training, we roll out the guide-policy for a fixed number of steps so that the agent is closer to goal states. The exploration-policy then takes over and continues acting in the environment to reach these goals. As the performance of the exploration-policy improves, we gradually reduce the number of steps that the guide-policy takes, until the exploration-policy takes over completely. This process creates a curriculum of starting states for the exploration-policy such that in each curriculum stage, it only needs to learn to reach the initial states of prior curriculum stages. Here, the task is for the robot arm to pick up the blue block. The guide-policy can move the arm to the block, but it cannot pick it up. It controls the agent until it grips the block, then the exploration-policy takes over, eventually learning to pick up the block. As the exploration-policy improves, the guide-policy controls the agent less and less. Comparison to IL+RL BaselinesSince JSRL can use a prior policy to initialize RL, a natural comparison would be to imitation and reinforcement learning (IL+RL) methods that train on offline datasets, then fine-tune the pre-trained policies with new online experience. We show how JSRL compares to competitive IL+RL methods on the D4RL benchmark tasks. These tasks include simulated robotic control environments, along with datasets of offline data from human demonstrators, planners, and other learned policies. Out of the D4RL tasks, we focus on the difficult ant maze and adroit dexterous manipulation environments. Example ant maze (left) and adroit dexterous manipulation (right) environments.For each experiment, we train on an offline dataset and then run online fine-tuning. We compare against algorithms designed specifically for each setting, which include AWAC, IQL, CQL, and behavioral cloning. While JSRL can be used in combination with any initial guide-policy or fine-tuning algorithm, we use our strongest baseline, IQL, as a pre-trained guide and for fine-tuning. The full D4RL dataset includes one million offline transitions for each ant maze task. Each transition is a sequence of format (S, A, R, S’) which specifies what state the agent started in (S), the action the agent took (A), the reward the agent received (R), and the state the agent ended up in (S’) after taking action A. We find that JSRL performs well with as few as ten thousand offline transitions. Average score (max=100) on the antmaze-medium-diverse-v0 environment from the D4RL benchmark suite. JSRL can improve even with limited access to offline transitions. Vision-Based Robotic TasksUtilizing offline data is especially challenging in complex tasks such as vision-based robotic manipulation due to the curse of dimensionality. The high dimensionality of both the continuous-control action space and the pixel-based state space present scaling challenges for IL+RL methods in terms of the amount of data required to learn good policies. To study how JSRL scales to such settings, we focus on two difficult simulated robotic manipulation tasks: indiscriminate grasping (i.e., lifting any object) and instance grasping (i.e., lifting a specific target object). A simulated robot arm is placed in front of a table with various categories of objects. When the robot lifts any object, a sparse reward is given for the indiscriminate grasping task. For the instance grasping task, a sparse reward is only given when a specific target object is grasped. We compare JSRL against methods that are able to scale to complex vision-based robotics settings, such as QT-Opt and AW-Opt. Each method has access to the same offline dataset of successful demonstrations and is allowed to run online fine-tuning for up to 100,000 steps. In these experiments, we use behavioral cloning as a guide-policy and combine JSRL with QT-Opt for fine-tuning. The combination of QT-Opt+JSRL improves faster than all other methods while achieving the highest success rate. Mean grasping success for indiscriminate and instance grasping environments using 2k successful demonstrations. ConclusionWe proposed JSRL, a method for leveraging a prior policy of any form to improve exploration for initializing RL tasks. Our algorithm creates a learning curriculum by rolling in a pre-existing guide-policy, which is then followed by the self-improving exploration-policy. The job of the exploration-policy is greatly simplified since it starts exploring from states closer to the goal. As the exploration-policy improves, the effect of the guide-policy diminishes, leading to a fully capable RL policy. In the future, we plan to apply JSRL to problems such as Sim2Real, and explore how we can leverage multiple guide-policies to train RL agents. AcknowledgementsThis work would not have been possible without Ikechukwu Uchendu, Ted Xiao, Yao Lu, Banghua Zhu, Mengyuan Yan, Joséphine Simon, Matthew Bennice, Chuyuan Fu, Cong Ma, Jiantao Jiao, Sergey Levine, and Karol Hausman. Special thanks to Tom Small for creating the animations for this post.